Blog Post
3 min read
Monday Morning Quarterback: Super Bowl Advertising Really Works
The stands have emptied. The Broncos and the Panthers played a great game. And of course, Lady Gaga just might have been the best musical performance during the game…and possibly ever…I digress…
Now that the confetti has settled, advertisers are eagerly reviewing the data to see if they hit their goals. With spots running in the millions, advertising during the biggest game of the year is no pee-wee sport.
The Second Screen Phenomenon Strikes Again
In our post last week, we discussed our client, Wix, and the second screen phenomenon during their 2015 Super Bowl ad campaign.
During last year’s Super Bowl Wix saw a huge spike (a.k.a. an anomaly) of traffic when their ad aired on television. The data we examined proved that people actually watched and reacted to the ads by accessing the Web on a second device. So how did they fare this year?
Second Screen Behavior Continues
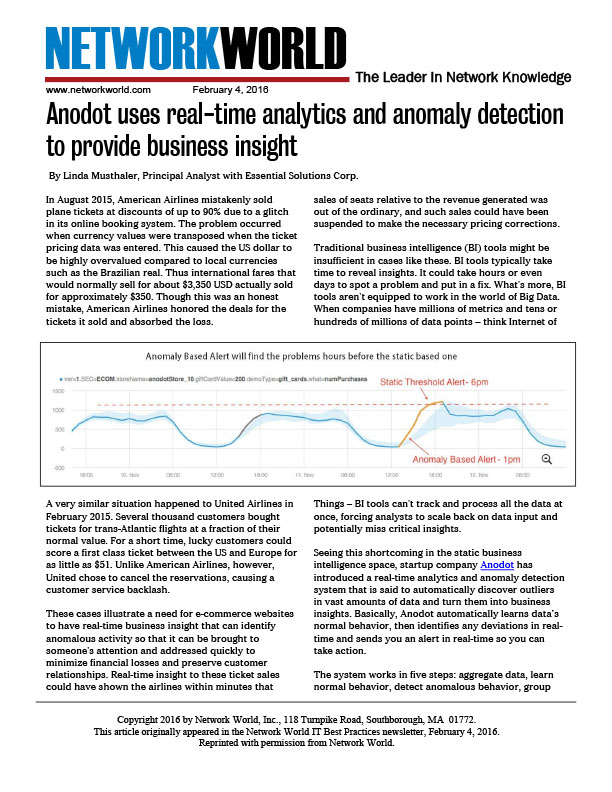
For the second year in a row, Wix came out a winner. Below is a graph showing the days leading up to the Super Bowl and the actual day of the game. Note the fairly regular seasonal pattern as the traffic goes up and down each day. Slide your eyes to the right and you can clearly see the spike in traffic. While the Anodot anomaly detection system correlated 240 (!) different application metrics with simultaneous anomalies, the two metrics shown here show jumps of more than 900% in one case, and more than 1000% in the other. In other words, a huge jump in traffic all over the site, including the sign-up page.
Note that the anomaly score for this traffic spike is 98, that is, 98 out of 100. In other words, not just a hop, but a huge, massive jump, worth taking note of, and a huge jump across hundreds of tracked metrics.
Now what about the second screen phenomenon that we witnessed last year? Sure enough, people are browsing from the closest thing at hand; mobile and tablet browsing to the Wix site jumped by 150% when their ad aired, while browsing from traditional PC “merely” doubled. Digital receivers, i.e. people browsing right from their TVs, while still only accounting for a tiny fraction of total traffic (so small, in fact, that you can barely see it on the graph below), saw a 1000% increase.
A Winning Campaign
With regard to last year, Wix’s VP Marketing Omer Shai said in an interview with Fortune: “We did pretty good in terms of the amount of money we got back from the campaign we did. It gave us great confidence in doing it [another Super Bowl ad] again.”
What’s great for Wix is that since they are a web-based business, with optimized pages they can immediately convert a large portion of their Super Bowl traffic into business. These traffic results are on par with what any advertiser could hope for following a large scale campaign like this. So…who’s going for an advertising touchdown in 2017?
Read more