Blog Post
7 min read
Transaction Metrics Every Fintech Operation Should be Monitoring
Fintech Metrics: Critical Transaction KPIs to Monitor
In a previous post about payment transaction monitoring, we learned how AI-based payment monitoring can protect revenue and improve customer experience for merchants, acquirers and payment service providers. In this post, we’ll highlight the critical transaction metrics that should be monitored in order to achieve these goals.
When most organizations think about ‘transaction metrics’ they probably think the KPIs are only relevant to BI or analytics teams. Measuring and monitoring payment metrics and other data doesn’t take priority in running the daily affairs of Fintech operations. Or does it?
What if we told you that the opposite is true. If Fintech companies want to protect revenue, payment operations teams must be able to find and fix transaction issues as they’re happening. In an increasingly digitized and competitive environment, no one can afford to wait for periodic reports to provide the necessary insights to run and optimize their daily operations.
It’s time for data to be approachable and understandable to all business units, and we’ll explain why in this post. Read on to discover how to improve transaction metrics monitoring to meet the challenges that lie ahead - or on your table right now.
Using transaction data proactively
Transaction processing metrics are significantly more complex to monitor than most digital metrics like web traffic or engagement. On top of the financial responsibility and risks, teams are dealing with heightened operational complexity. Just think how many steps are necessary for a single transaction on your site and how many parties are entangled. Many stages require verification, authentication, and approval. It’s never just a click.
With so many intersections and points of friction, there’s a lot that can potentially go wrong. A glitch in any of the related algorithms, APIs, or other functionalities can cause chain reactions in a whole series of processes and immediately lead to reduced customer satisfaction and eventually to a loss of revenue.
It also means there are many opportunities to optimize processes and increase efficiency. At each link in the chain, there’s something to improve. To make both possible - detect failures and opportunities - it’s critical to monitor the entire set of digital payment metrics.
Currently, that’s in the hands of the BI or IT teams. Operational teams depend on standardized reports of historical data after it passes through the relevance filters of the data analysts. You may be missing specific transaction metrics that could provide a valuable understanding of how consumers behave or point towards weaknesses in the operational processes. You are definitely losing time when it comes to identifying failures.
Why organizations need more granularity for payment metrics
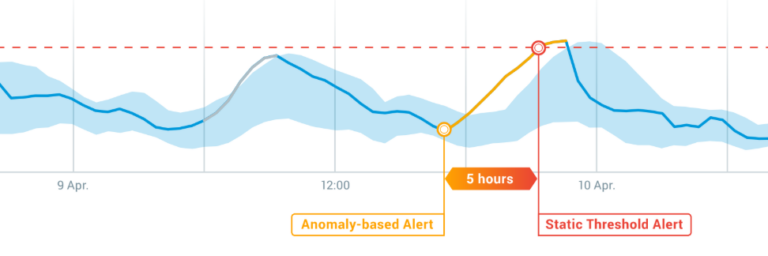
The amount of data and metrics to monitor has become overwhelming even for the dedicated business units. There are only so many dashboards a human being can observe. To remain efficient, they currently focus on critical business metrics and generalized data. Alert systems notify about irregularities based on manually set static thresholds, causing alert storms when there are natural fluctuations.
Let’s imagine transaction performance metrics show a decrease, and the data you receive helps you identify a reduced payment approval rate. That’s still a pretty general observation that creates more questions than answers. A more granular view of the data, such as by location, vendor, payment method, device, and so on, could deliver insights that point you towards the cause.
The same is true for optimization efforts. With a deeper level of granularity, companies can pinpoint weaknesses and strengths more precisely and act upon them with a higher chance of success. You can easily identify your highest-performing affiliates or discover the geographical locations you are most popular in.
[CTA id="7a3befd2-2d16-4944-af32-574e0a11e90d"][/CTA]
Revenue-critical KPIs to monitor
Because there are so many metrics and dimensions to measure across the payment ecosystem, it’s important to focus on the most critical KPIs. Fintech operations teams should make sure they have accurate and timely insight into the following metrics:
Payment approval - compare payment requests vs. payments approved. With Anodot you can identify discrepancies on the spot and reduce the time to identify and fix issues.
Merchant behavior - measure the number of transactions, financial amounts, and more. Anodot lets you analyze merchant behavior and uncover ways to optimize marketing and business.
Vendor routing - evaluate your payment providers. Anodot helps you focus your efforts on the strongest vendors.
APIs - nothing goes without functioning APIs in fintech. With Anodot you can easily monitor the functionality and ensure smooth processes.
Deposits and settlements - monitor the two layers for payment. Use Anodot to stay on top of the entire payment process and increase efficiency.
Processing intervals - keep an eye on the time it takes for payments to go through. With Anodot you’ll know right away when there’s a delay somewhere in the system and can avoid customers being disappointed and abandoning your site.
The benefits of real-time payment metrics
The problem with the current method of analyzing transaction metrics analysis is that data is historical, too generalized, and not effectively prioritized. In other words, by the time the information reaches you, it already belongs to the past. Strictly speaking, decisions are based on outdated information.
Real-time data enables you to see and react to what’s happening right now. That may not sound all that beneficial at first. Some people even find the thought of having to respond in real-time stressful. But monitoring real-time data doesn’t mean you sit around watching your data monitor like a flight supervisor.
Back to the payment approval issue; The tool correlates out-of-the-ordinary data behavior and finds related incidents in real-time. Instead of you - or a data person - digging up possible related metrics and creating reports to see what caused the drop, the tool points you towards the cause and the solution.
How AI makes data accessible to more business units
Anodot’s AI-driven business monitoring tool learns normal data behavior patterns, taking seasonal changes and fluctuations into consideration to identify anomalies that impact business. Anodot monitors all your business data and learns the behavioral patterns of every single metric. The monitoring goes on even when you are not looking, distilling billions of data events into single relevant alerts.
Anodot also correlates irregularities in transaction metrics with other data and notifies the relevant business units. This means, when you receive an alert, it contains maximum information to help you get to the bottom of what’s happening and how things are connected.
Let’s say you detect a drop in deposits. Anodot correlates all related metrics and identifies that all activities with a specific vendor are down, so the failure is with that particular vendor. You are a huge step closer to the next phase of problem-solving.
Anodot also prioritizes and scores the severity of an alert based on its financial impact. You only get notified about the metrics that are relevant and need immediate attention.
Autonomous payment metrics monitoring for higher efficiency
Only an AI/ML-based solution that autonomously monitors all metrics, correlating and prioritizing data, can ensure that each business units receive the insights they need when they need it.
The days where data was the sole domain of a chosen few are over. In today’s digitalized business environments, data is everywhere and needs to be accessible to those who need it most. Monitoring data is part of a daily routine, just like keeping an eye on the fuel gauge in your car to know when you need to refill.
Read more