Videos & Podcasts
0 min read
Anodot for Payments: Detect and Resolve Incidents Faster
Find out why global companies like Payoneer, are using Anodot to detect and resolve operational incidents before they impact revenue and customers.
The digital transformation and decentralization of the fintech segment has resulted in increasing complexities in payment transactions, more third party applications and a higher volume and velocity of payments data that need to be monitored in real-time.
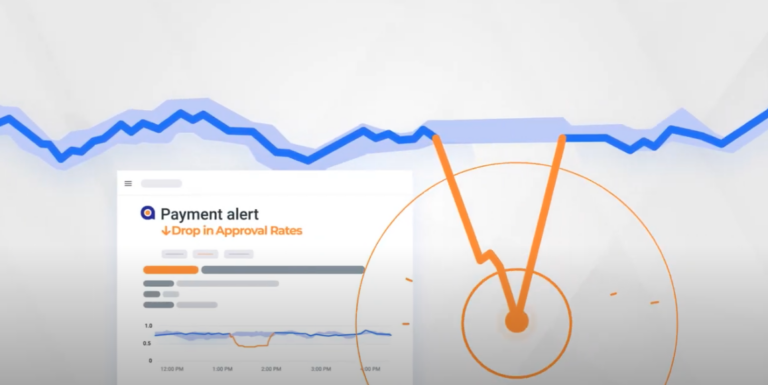
To make sure every payment transaction is completed as expected, payment operations teams must be able to find and fix payment issues as they’re happening anywhere along the end-to-end transaction path. Whether you’re a merchant, acquirer, or payments processor, it’s crucial to have complete visibility into your payments environment.
Anodot’s powerful and easy-to-use anomaly detection and triage technologies help fintechs stay on top of their operations, deliver flawless customer experience, and optimize approval rates and fees.
Anodot’s AI-driven platform learns the expected behavior across all permutations of digital banking — including payment approvals, merchant activity, partner APIs, deposits and withdrawals, login attempts, and more — and alerts teams in real-time to any incident, delivering the full context of what is happening, where and why.
Watch