
The Importance of Outlier Detection
Whether they indicate a substantial business problem or an opportunity for performance and revenue optimization, detecting outliers is mission critical for companies of all sizes. In scouring time series data, knowing how to detect outliers is an important task that cannot be overlooked.
Looking for unusual data points by manually examining every metric, however, is impractical for more than a few dozen metrics. This is why more and more companies are looking into different outlier detection approaches to help them overcome this hurdle.
Build vs. Buy: Deciding on an Outlier Detection System
As companies realize the benefits they can achieve from automated outlier detection rather than with the manual dashboard monitoring and alerts used in traditional BI tools, they’re faced with the immediate question: build our own system or buy one?
For companies with small amounts of data or who do not need analytics in real time, a simple home-grown solution may be sufficient. However, developing an outlier detection system in-house would take even the most experienced professionals one to two years, and even after deployment, still require their involvement in maintaining the system. This effort could distract valued team members from their company’s core mission and may still not take the endless amounts of metrics into account.
The Benefits of an Off-the-Shelf Solution
Rather than developing an in-house system, companies may realize more value by adopting an existing product. A comprehensive and sophisticated off-the-shelf outlier detection system offers considerably more benefits and faster time to value than those developed in-house, without the need for ongoing maintenance nor a dedicated development team.
Don’t underestimate the cost of building outlier detection
As we explained in the previous post, “Calculating risk: how to find and calculate outliers in your data using automated anomaly detection system”, the challenges include selecting the appropriate outlier detection method for each metric, tuning it, and constantly re-evaluating that choice in case the metric itself switched to a new normal behavior – all without human interaction.
The option to build is usually only viable for companies with small amounts of uncomplicated data or extremely large, innovative companies that have a dedicated team.
Depending on the number of variables to be captured in the system, as well as the availability of trained staff to develop the system, some build scenarios could take more than five years to develop, particularly for large, complex, and changing data needs. Costs are highly dependent on the type of solution the organization chooses to pursue. For small amounts of data, a rudimentary outlier detection solution might serve their needs. Yet, for larger quantities of data metrics, a more robust outlier detection system that includes scoring and correlation is a must.
Even for the small company, doing business in a small, limited region, the number of metrics to monitor may grow quickly, and you essentially “scale out” of the feasibility of implementing your own outlier detection approach. For example, if you’re an online bike retailer and offer three different bicycle models, sell to all 50 US states, and support four different browsers (Edge, Chrome, Firefox and Safari) running on five different operating systems: Windows 10 & 7, Android, macOS and iOS, the total possible number of revenue metrics this will produce is:
| Models | States | Browsers | Operating Systems | Total |
| 3 | 50 | 4 | 5 | 3000 |
This grows as you add more KPIs (e.g., number of users) and different versions of each supported OS.
Actually detecting outliers quickly and accurately (i.e. very low false positives and false negatives) without overwhelming your analytics team with alert storms requires not only top-notch implementations of all the relevant outlier finding algorithms (some of which can be computationally expensive), but also implementing a meta-algorithm to choose on the fly which one to use for which metric at which time. Then there’s detecting and accounting for any seasonality, and correlating related anomalies together to give a concise picture of what’s causing those outliers.
It doesn’t stop with metrics directly related to revenue, either. Do you make the bikes yourself from parts you purchase? If so, you have metrics like inspection rejection rate per part number and vendor. Does your bike shop employ anybody other than you? If that’s the case then you can also gather data on churn rate, employee satisfaction and performance, monthly benefits cost, etc. Whether it’s page load times, mobile app uninstalls, or average revenue per customer, metrics are everywhere, and an automated outlier detection system allows you to get the most insight out of all of them in the quickest amount of time.
Detecting outliers with a solution that scales
For a company with far fewer metrics than our hypothetical online bike shop, it may be sufficient to create some dashboards and alerts to track outliers.
As small companies grow, however, the whole cost/benefit analysis shifts, and they end up eating the savings from having built a homegrown solution when they have to dedicate more resources to growing amounts of metrics to monitor and find themselves manipulating dashboards all day.
Here’s a chart with a good breakdown of development costs:
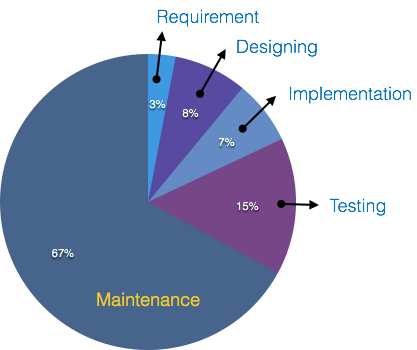
For a company that has dedicated data science resources and decides to build their own outlier detection solution, they may find that they are devoting their time to something that, while critical to the success of the company, can be better solved by an off-the-shelf solution. For example, data scientists may spend up to 80% of their time cleaning data. If they spend the rest of their time maintaining an outlier detection solution, they have no time to generate value.
The issue for companies to face is do they want to be in their software development effort or apply their minds to furthering their actual core business. Building a usable outlier detection system requires not only data scientists and programmers, but also UI/UX experts and QA personnel, all of whom are in short supply and command high salaries.
The business case for buying: the ultimate outlier detection approach
The obvious costs for the “build” option include the aforementioned staffing, maintenance costs (cloud subscriptions or in-house hardware), and opportunity costs as other personnel are pulled away from their usual jobs to help with defining requirements, testing, feedback, etc. In addition to those, there are other, less obvious costs.
Other costs occur around time to value, including the losses incurred by undetected outliers, as well as losses due to problems which were spotted hours, days or weeks after they first began (instead of minutes as with Anodot’s solution). In an era when unplanned downtime costs an average of $5,600 per minute, companies can’t afford to miss any signs of trouble.
Total solution cost is another compelling reason to buy an off-the-shelf outlier detection system, especially as those costs are compounded by scale as the company, product line or market grows. Furthermore, the customization which also initially leads companies towards the “build” route is actually better achieved by the advanced machine learning algorithms built into mature solutions.
For the overwhelming majority of businesses, buying an outlier detection system gives them a shorter time to value and a greater overall value than building in-house. Besides, companies are more inclined to focusing their energy on building their profit margin, than building their own outlier detection system.
Looking for the full comparison of whether to build or buy? Download this white paper.
Written by Ira Cohen
You'll believe it when you see it



