Hybrid Fiber Coaxial (HFC) networks are inherently agile and able to adapt to demand spikes. This significant characteristic was most recently demonstrated by their success in handling pandemic-induced traffic surges. That’s why during the past year cable operators have prioritized HFC over FTTH projects, adding capacity to their HFC networks, pushing ahead with node splits, and accelerating the use of AI-assisted technologies that enable networks to use the existing spectrum more efficiently.
HFC monitoring challenges
There is, however, a significant downside to HFC networks: according to a recent article by Light Reading, despite its robustness and agility, changes in end-user behavior are still imposing customer experience and network planning challenges for HFC network operators. The complexity of the network and infrastructure make it extremely difficult to understand performance degradations proactively. CSPs face daily issues in the HFC segment of their network where late and reactive issue detection creates a negative impact on OPEX efficiency and customer experience, with a potentially adverse effect on revenues and churn.
A typical HFC network generates millions of metrics at various parts of the network. For example, a single cable modem can generate around 300 KPIs (there are millions of cable modems in the network), and thousands of additional metrics generated by the access, edge, core, backbone and interconnected layers.
Monitoring multiple disparate metrics represents significant challenges: Metrics are generated by multi-vendor technologies in silos; existing manual tools and methodologies are often inadequate in detecting issues quickly, identifying the root cause, or offer any assistance in cutting the mean-time-to-repair (MTTR). For HFC networks, this is especially important in the context of slow leaks. Since very often failure indication takes time due to service or network element degradation, slow declines take long to reach the static threshold level. In addition, when subscribers experience uplink and downlink incidents such as throughput drops or packet loss there is no way to generate a coherent view of the root cause. This often leads to an increase in customer complaints, loss of brand reputation, and, more importantly, increased OPEX.
Effective monitoring for HFC networks
In order to build confidence and scale the upstream/downstream capacity of HFC networks, CSPs need to create the monitoring environment that provides the transparency needed to seamlessly identify and mitigate any issues as quickly as possible.
Monitoring complex multi-vendor environments has never been easy. As broadband usage increases at a rate of 20-25% CAGR, identifying failures is becoming increasingly difficult. It’s not surprising that engineers list monitoring as a major obstacle for HFC networks.
Manual alerts and thresholds are a non-starter when it comes to HFC networks. CSPs run multiple hybrid networks, each with a large number of nodes, making static alerts completely impractical. Manual, or even semi-autonomous monitoring platforms will inevitably produce alert storms (too many false-positives)—or you could miss key events (false negatives).
By adopting an autonomous monitoring solution like Anodot, CSPs can use machine learning to constantly track millions of HFC events in real time and be alerted to anomalies and issues when needed. Machine learning based anomaly detection for HFC networks directly improves customer experience and increases OPEX efficiency in HFC.
Zero-touch HFC network monitoring
Anodot’s autonomous network monitoring platform is the brain on top of the OSS, giving CSPs a holistic view across multi-vendor HFC environments for real time detection of service-impacting incidents. With Anodot, CSPs can identify issues as they happen, and proactively take actions or make changes before they dramatically impact the customer’s experience — and the business.
In the example below, Anodot detected an anomaly in downstream throughput for a specific CMTS:
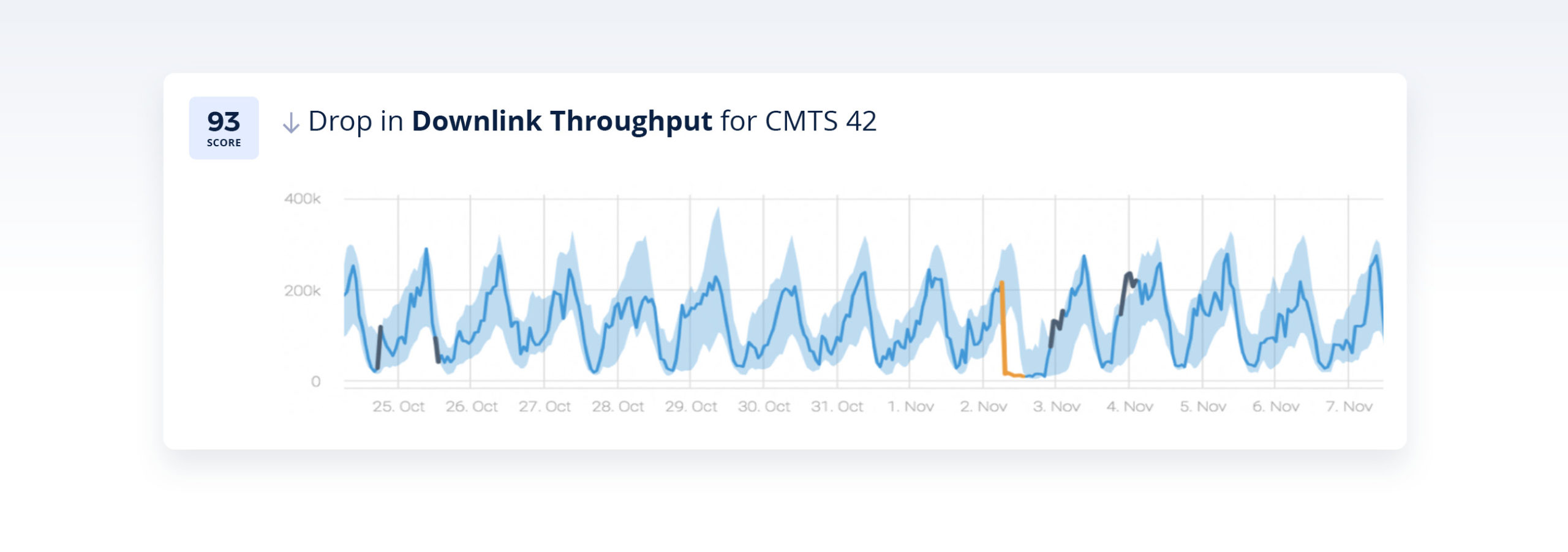
By correlating between anomalies across the network, Anodot was able to correlate the incident above to the following incidents:
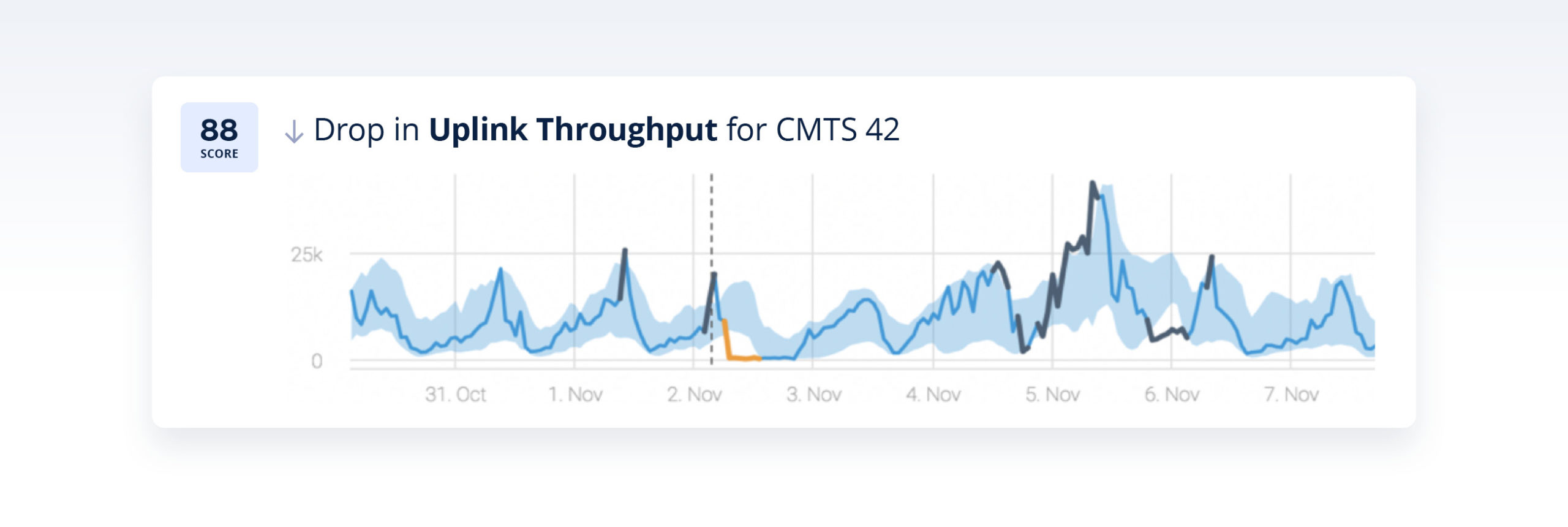
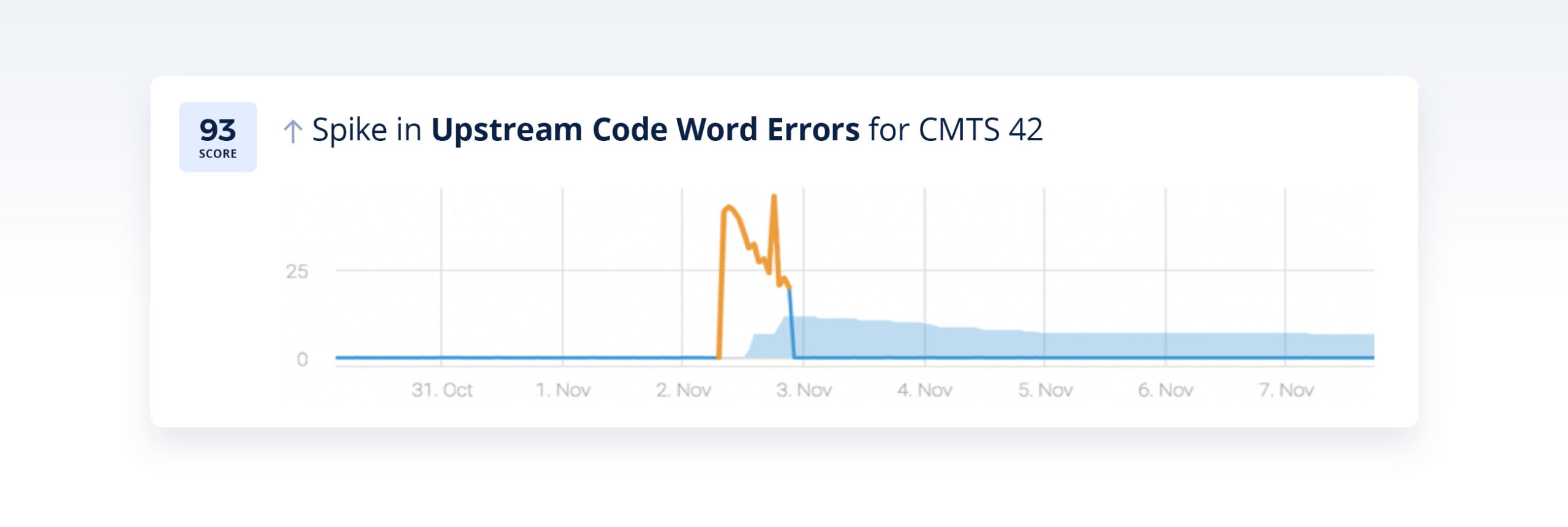
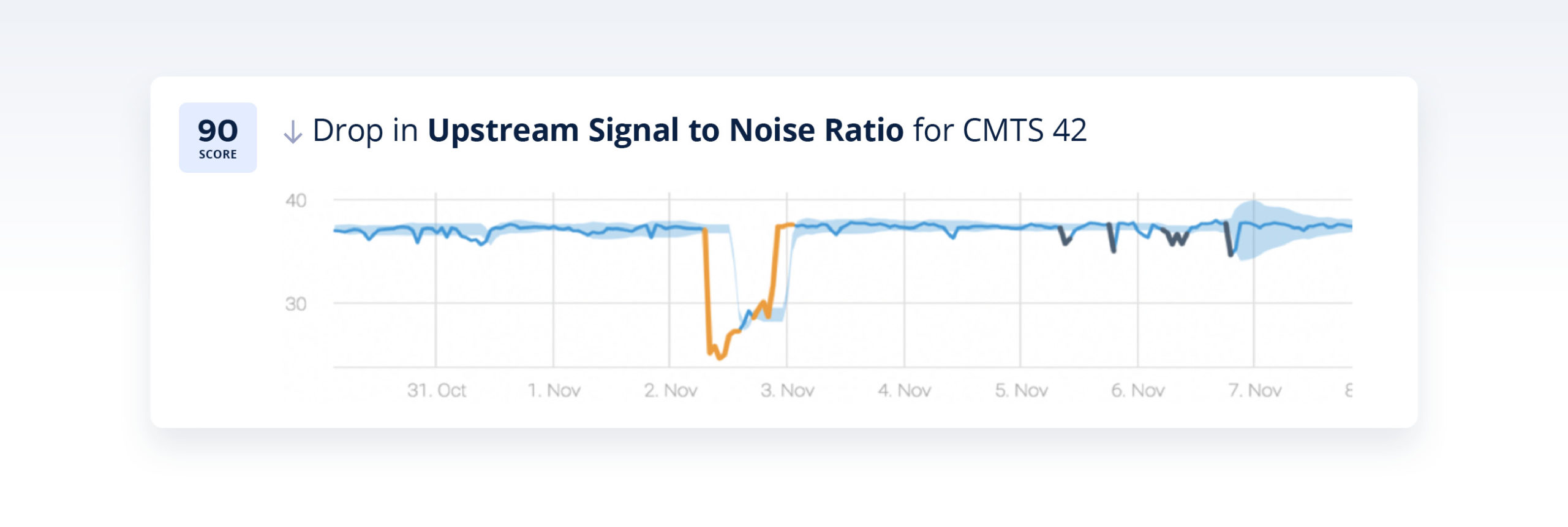
Based on these incidents, the CSP was able to proactively notify customers in the region about the service degradation, creating a better customer experience and taking a load off customer service complaints. In addition, by relying on the correlated anomalies that caused the incident the technical team was able to resolve the issue much faster than in previous cases.
Download our White Paper to learn more about how machine learning-based anomaly detection solutions like Anodot enable CSPs to take their HFC networks to the next level.